both are in the “classic statistics” book, and may involve hypothesis testing
both deal with two continuous variables
both look at (first order) linear relations
when correlation is significant, the regression slope is significant
Differences:
Regression distinguishes \(y\) from \(x\): \(y\) depends on \(x\), not reverse;
the line \(y=ax+b\) is not equal to the line \(x = cy + d\)
Correlation is symmetric: \(\Cor(x,y)=\Cor(y,x)\)
Correlation coefficient is unitless and within \([-1,1]\), regression coeficients have data units
Regression is concerned with prediction of \(y\) from \(x\).
The power of regression models for spatial prediction
… is hard to overestimate. Regression and correlation are the fork and knife of statistics.
linear models have endless application: polynomials, interactions, nested effects, ANOVA/ANCOVA models, hypothesis testing, lack of fit testing, …
predictors can be transformed non-linearly
linear models can be generalized: logistic regression, Poisson regression, …, to cope with discrete data (0/1 data, counts, log-normal)
many derived techniques solve one particular issue in regression, e.g.:
ridge regression solves collinearity (extreme correlation among predictors)
stepwise regression automatically selects “best” models among many candidates
classification and regression trees
Why is regression difficult in spatial problems?
Regression models assume independent observations. Spatial data are always to some degree spatially correlated.
This does not mean we should discard regression, but rather think about
to which extent is an outcome dependent on independence?
to which extent is regression robust agains a violated assumption of independent observations?
to which extent is the assumption violated? (how strong is the correlation)
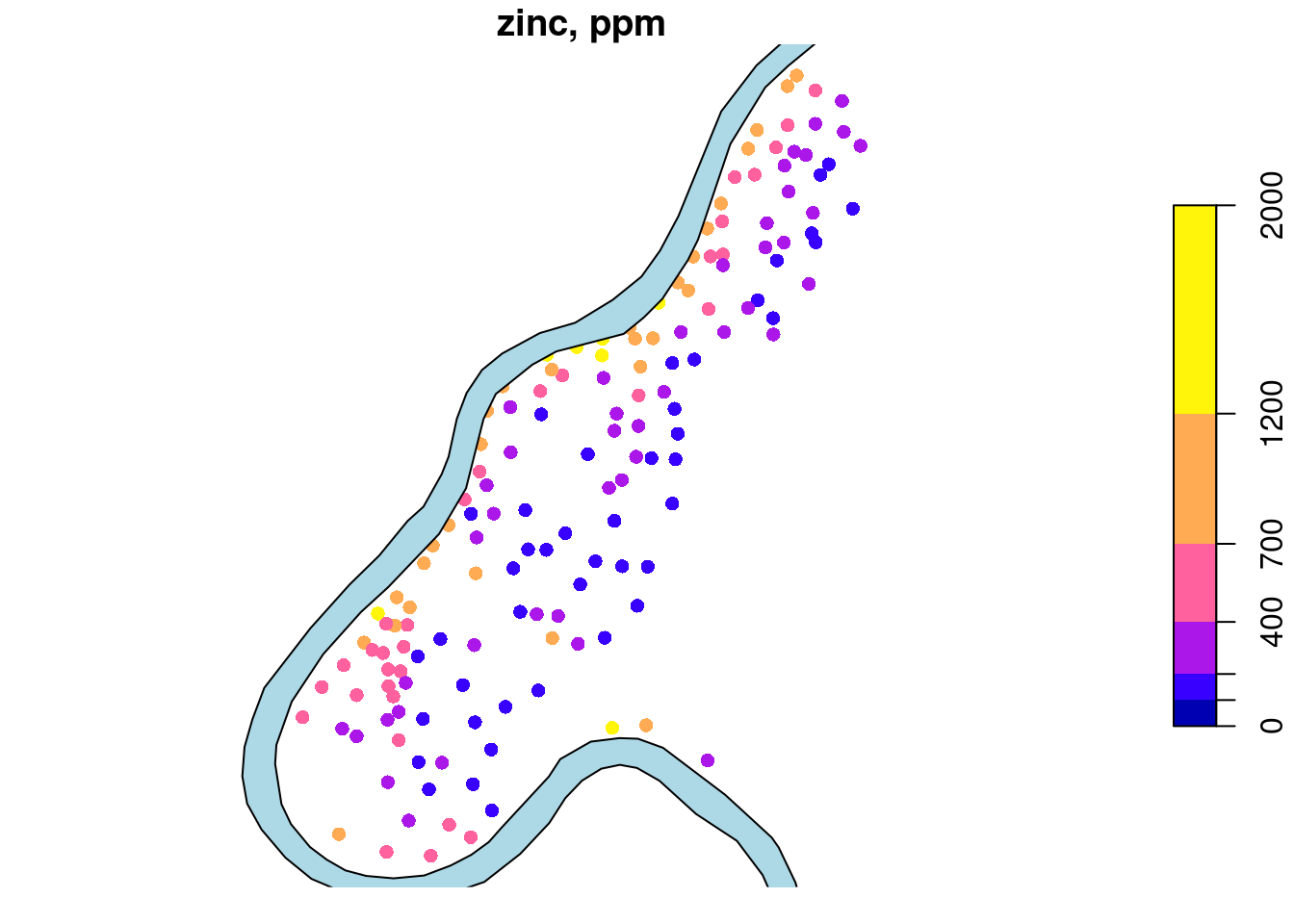
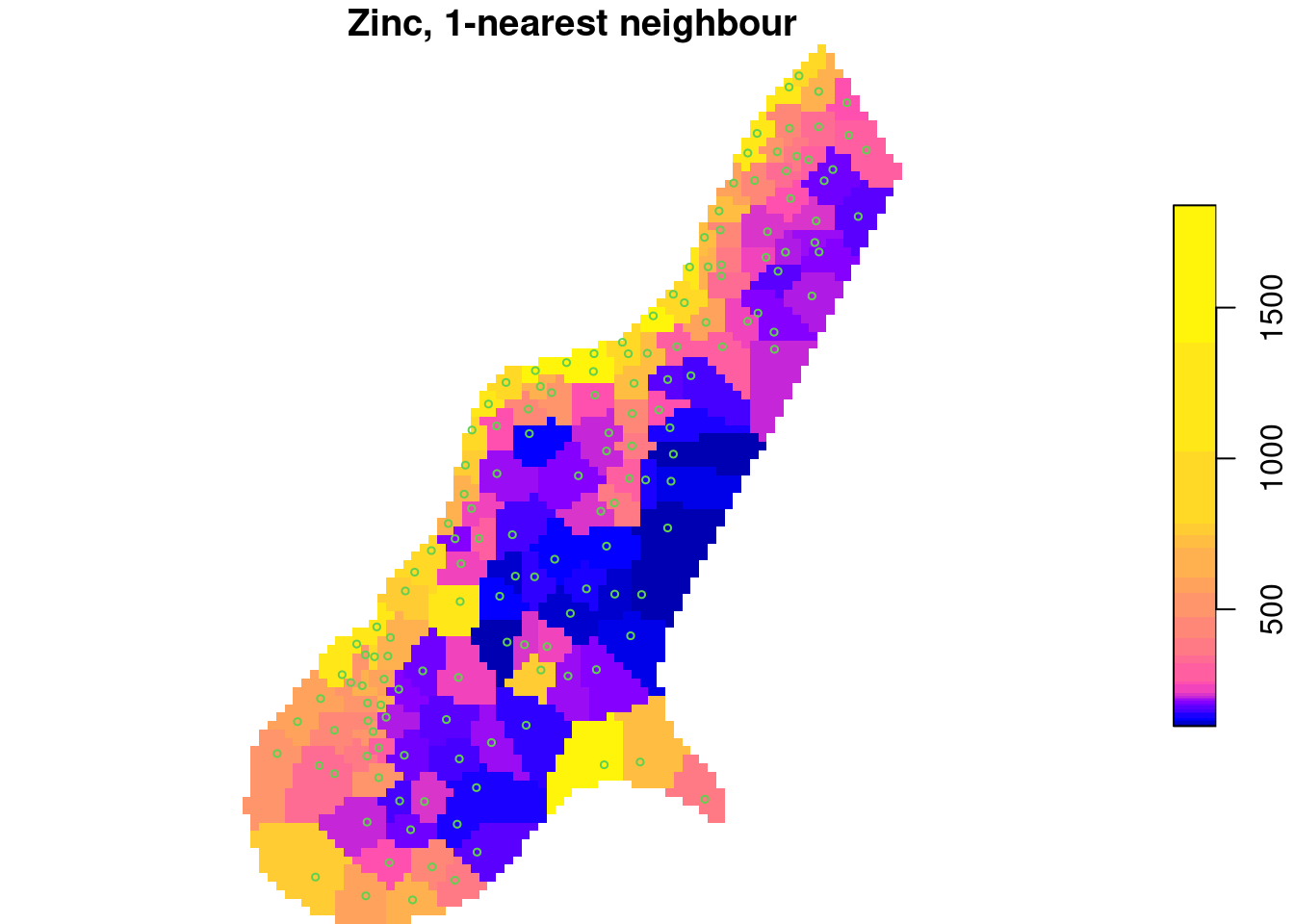
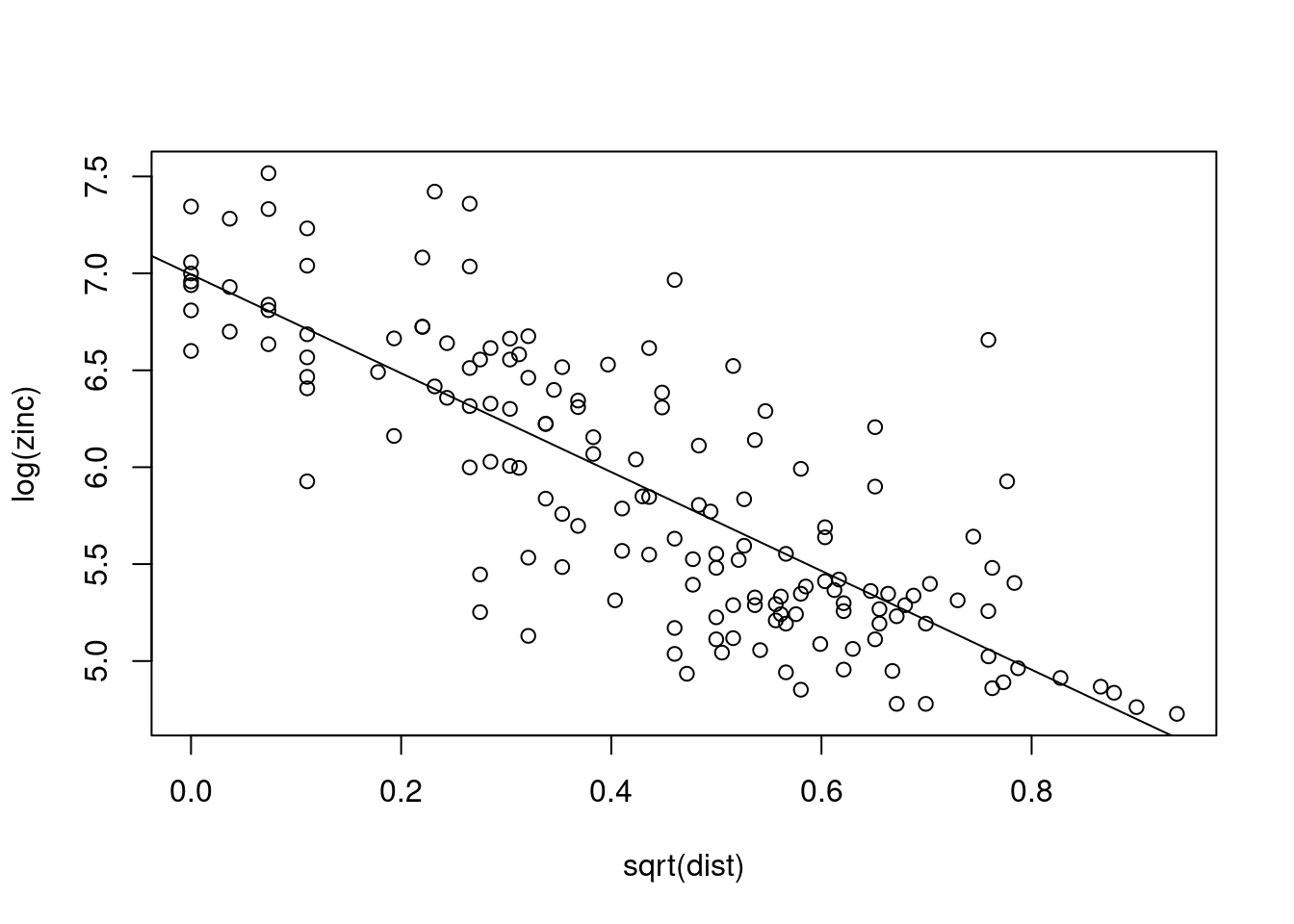
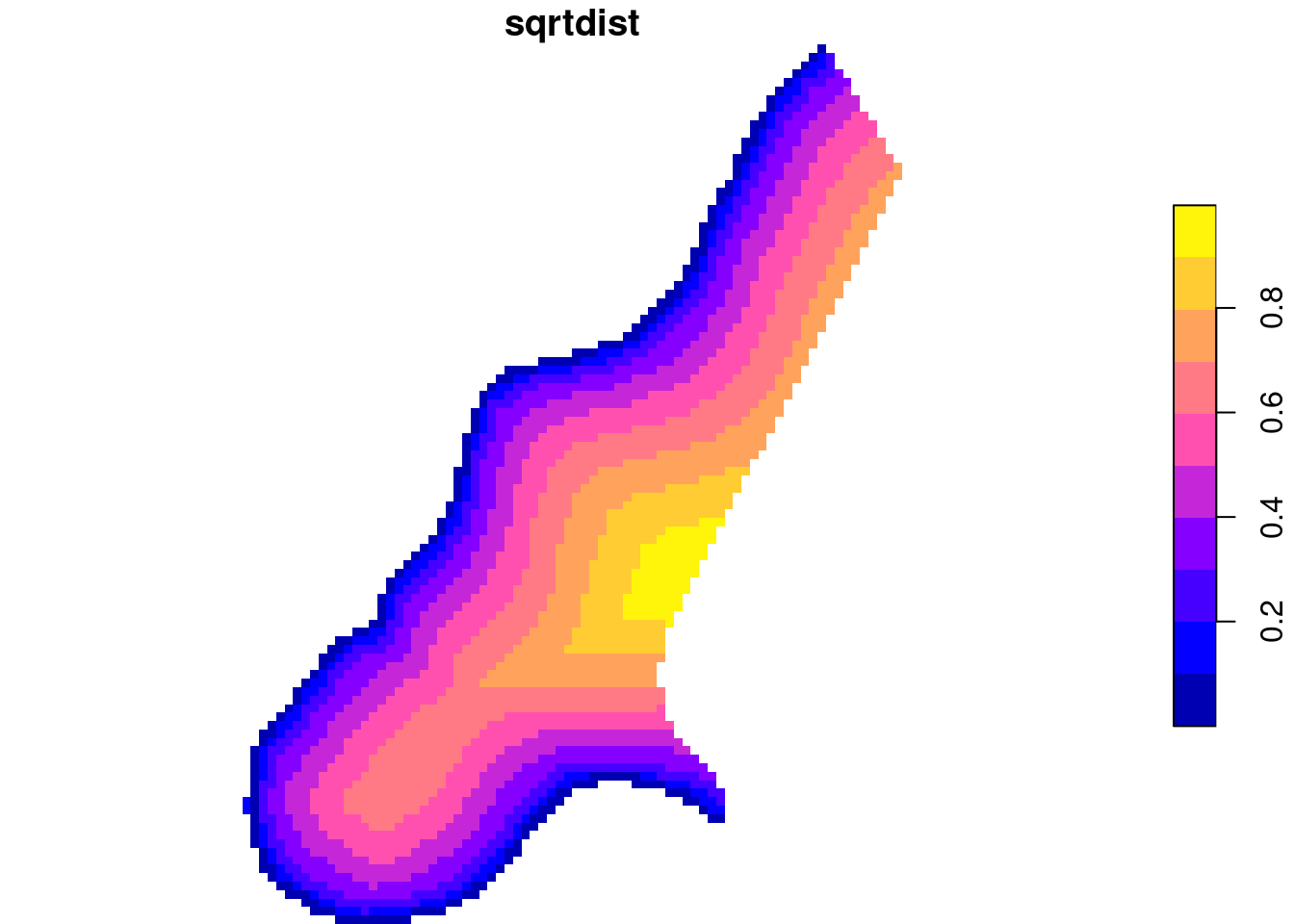
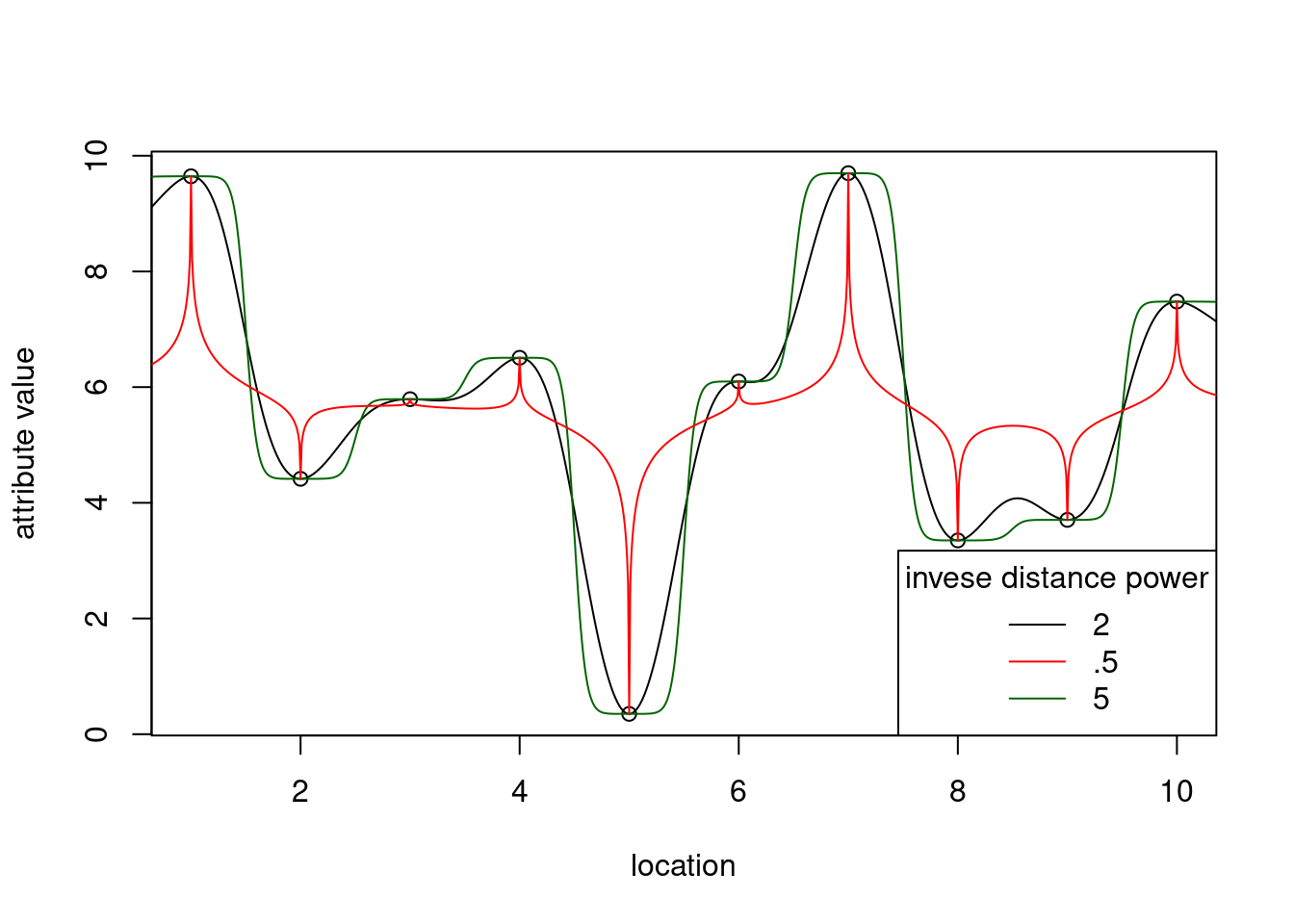
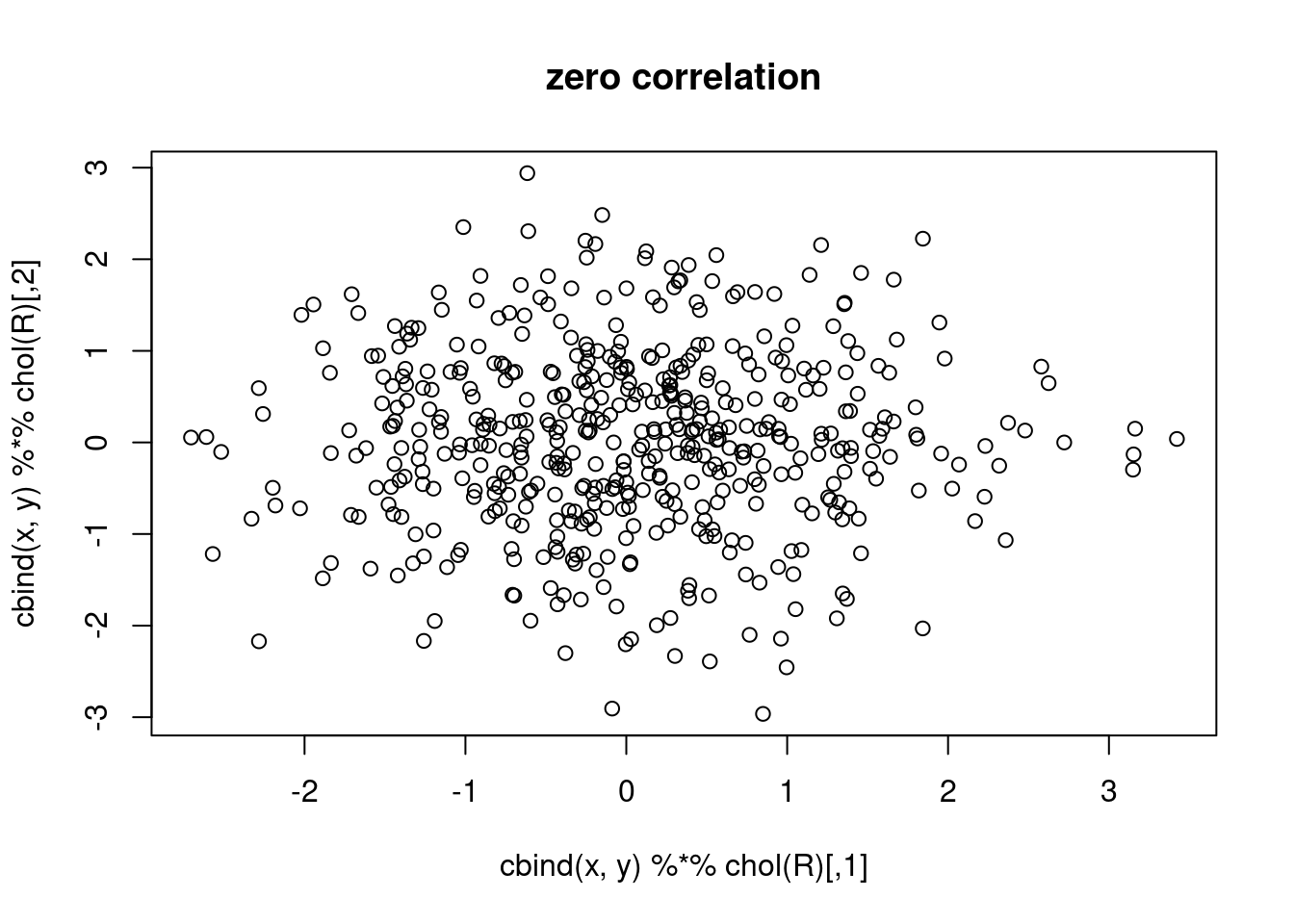
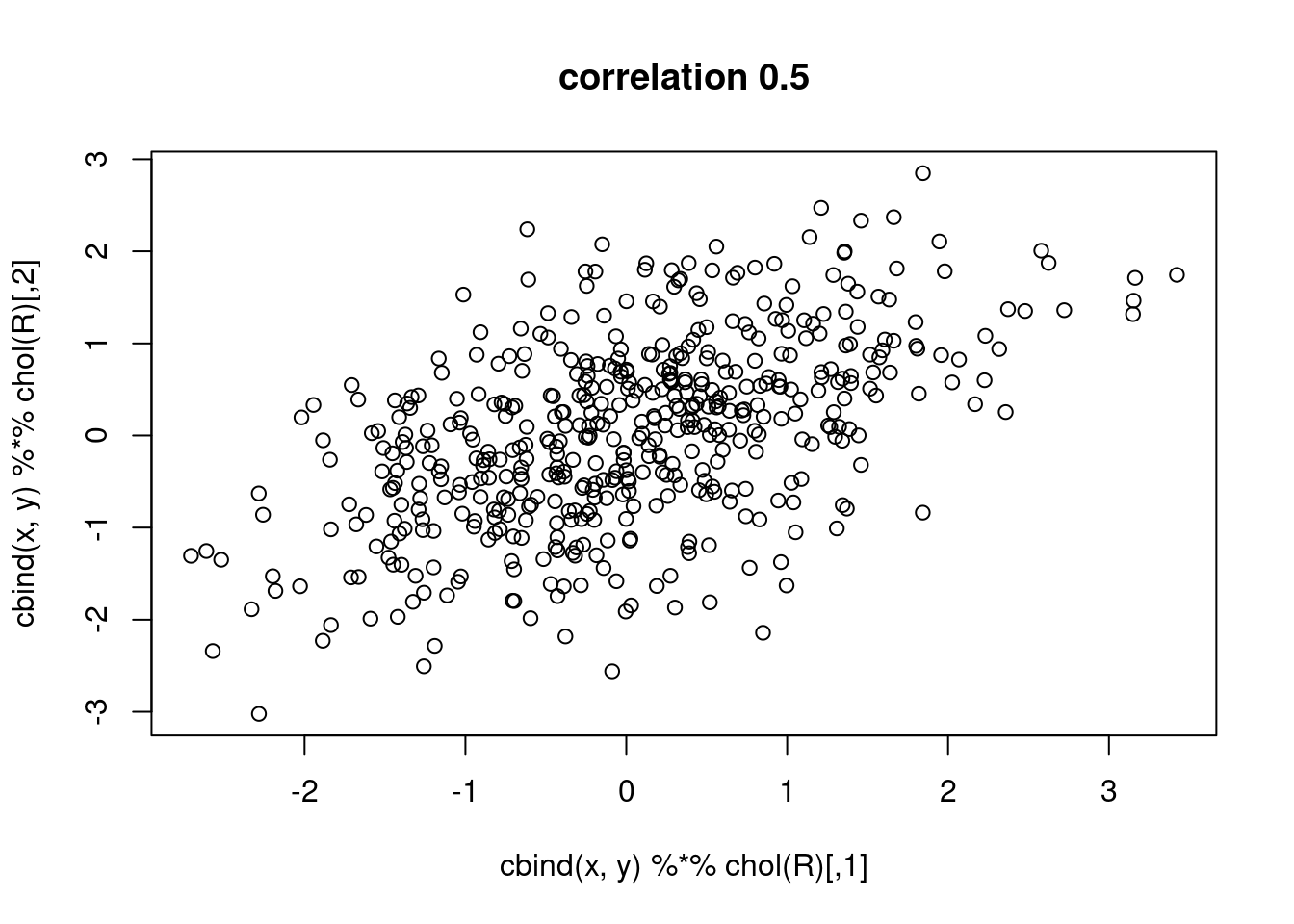
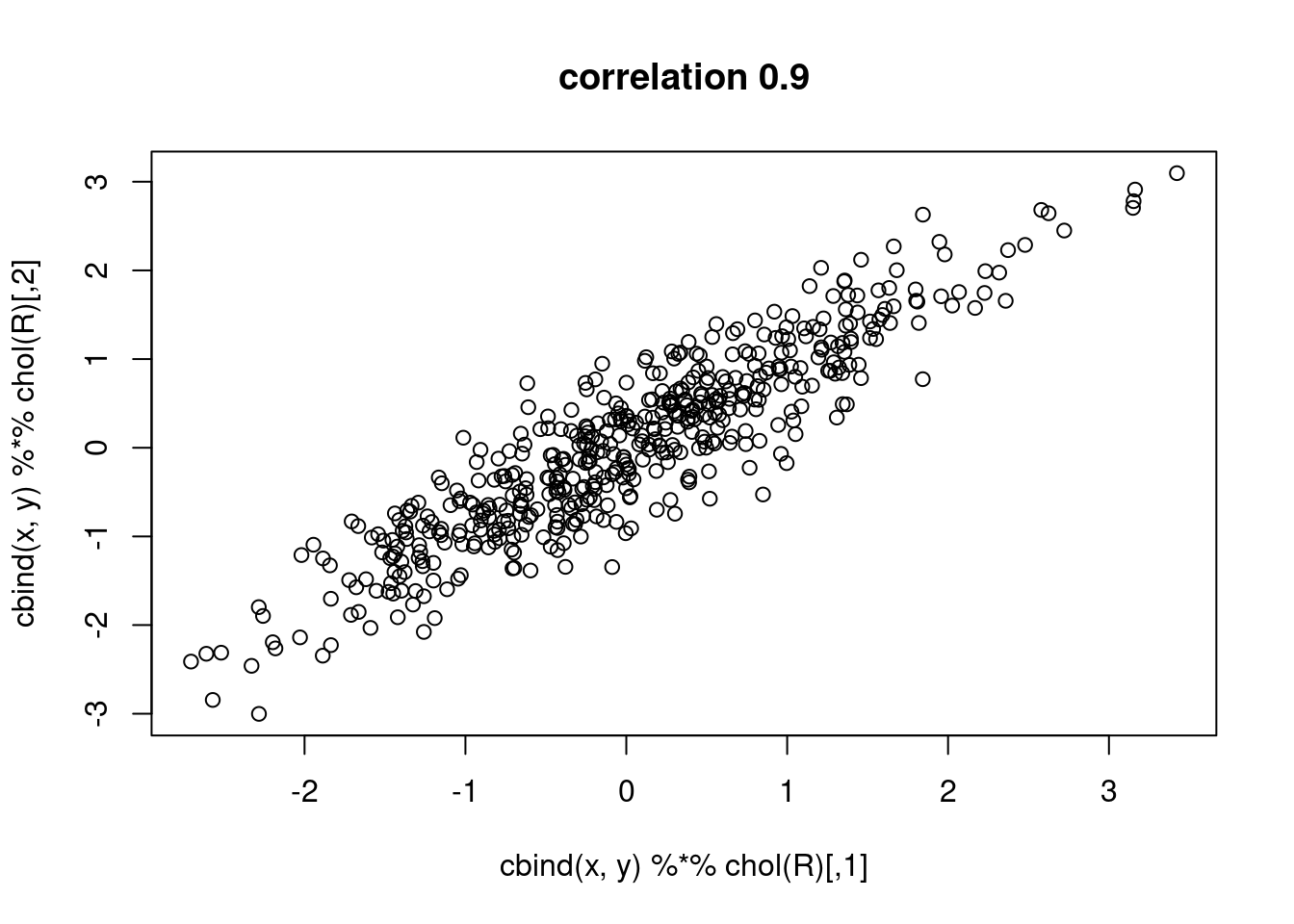
What is spatial correlation?
Waldo Tobler’s first “law” in geography: “Everything is related to everything else, but near things are more related than distant things.” (Tobler 1970)
Setting aside whether Tobler was the first to acknowledge this, and also whether the expression can be called a “law”, we wonder how being related can be expressed?
Tobler, W. R. 1970. “A Computer Movie Simulating Urban Growth in the Detroit Region.”Economic Geography 46: 234–40. https://doi.org/10.2307/143141.