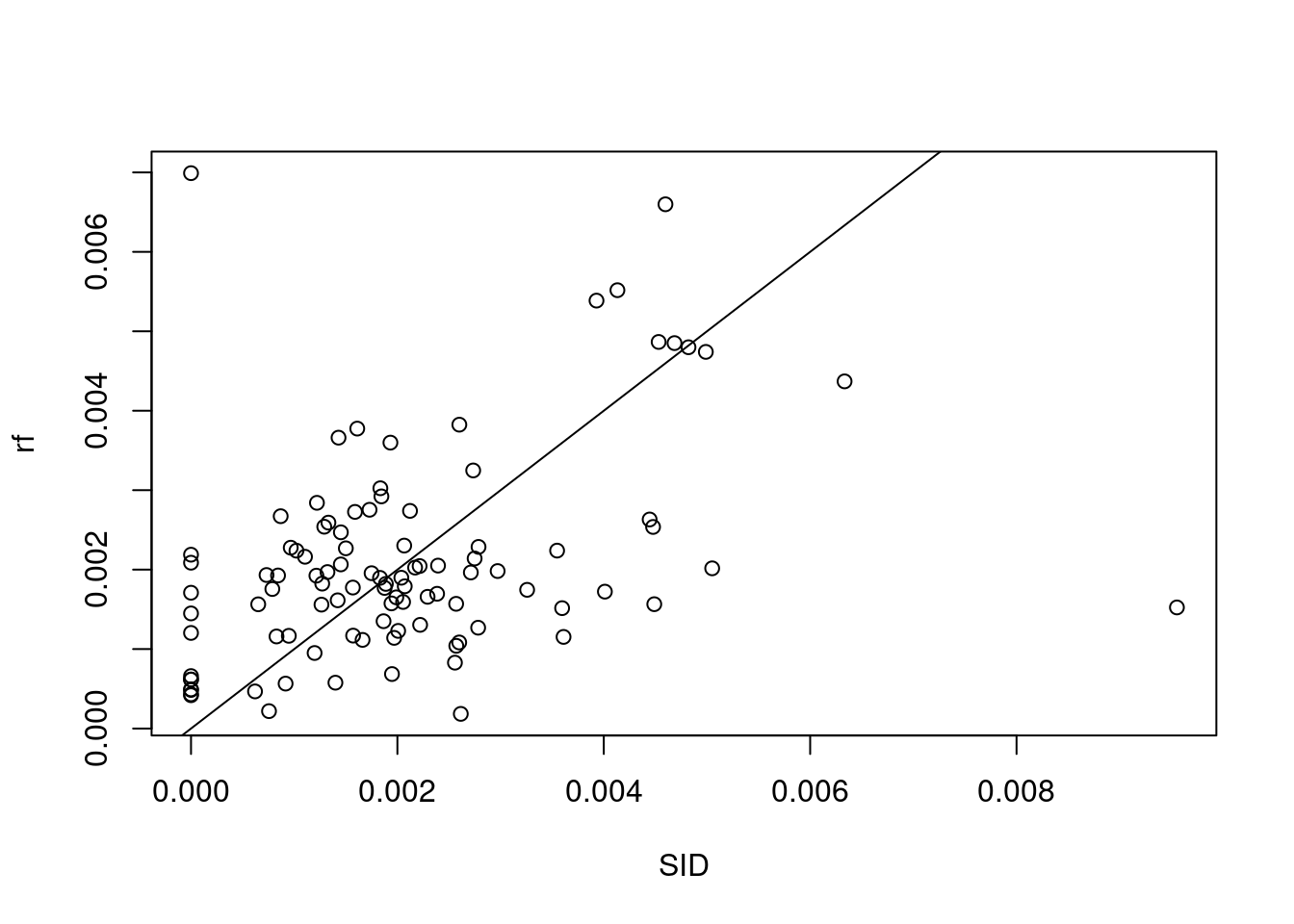
following the lm example of Section 10.2 use a random forest model to predict SID values (e.g. using package randomForest), and plot the random forest predictions against observations, along with the \(x=y\) line.
Create a new dataset by randomly sampling 1000 points from the nc dataset, and rerun the linear regression model of section 10.2 on this dataset. What has changed?
pts=st_sample(nc, 1000)nc2=st_intersection(nc1, pts)# Warning: attribute variables are assumed to be spatially constant# throughout all geometrieslm(SID~NWB, nc1)|>summary()# # Call:# lm(formula = SID ~ NWB, data = nc1)# # Residuals:# Min 1Q Median 3Q Max # -0.0033253 -0.0007411 -0.0000691 0.0005479 0.0062218 # # Coefficients:# Estimate Std. Error t value Pr(>|t|) # (Intercept) 0.0006773 0.0002327 2.910 0.00447 ** # NWB 0.0043785 0.0006204 7.058 2.44e-10 ***# ---# Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1# # Residual standard error: 0.001288 on 98 degrees of freedom# Multiple R-squared: 0.337, Adjusted R-squared: 0.3302 # F-statistic: 49.82 on 1 and 98 DF, p-value: 2.438e-10lm(SID~NWB, nc2)|>summary()# # Call:# lm(formula = SID ~ NWB, data = nc2)# # Residuals:# Min 1Q Median 3Q Max # -0.0032744 -0.0008045 -0.0000551 0.0005394 0.0062731 # # Coefficients:# Estimate Std. Error t value Pr(>|t|) # (Intercept) 7.575e-04 7.658e-05 9.891 <2e-16 ***# NWB 4.162e-03 1.991e-04 20.908 <2e-16 ***# ---# Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1# # Residual standard error: 0.001261 on 998 degrees of freedom# Multiple R-squared: 0.3046, Adjusted R-squared: 0.3039 # F-statistic: 437.1 on 1 and 998 DF, p-value: < 2.2e-16
we see that the standard error has decreased with a factor 3 (sqrt(10)).
drops for larger dataset, as this is dominated by the standard errors of estimated coefficients.
Exercise 10.3
Redo the water-land classification of section 7.4 using class::knn instead of lda.
Preparing the dataset:
tif<-system.file("tif/L7_ETMs.tif", package ="stars")library(stars)# Loading required package: abind(r<-read_stars(tif))# stars object with 3 dimensions and 1 attribute# attribute(s):# Min. 1st Qu. Median Mean 3rd Qu. Max.# L7_ETMs.tif 1 54 69 68.91242 86 255# dimension(s):# from to offset delta refsys point x/y# x 1 349 288776 28.5 SIRGAS 2000 / ... FALSE [x]# y 1 352 9120761 -28.5 SIRGAS 2000 / ... FALSE [y]# band 1 6 NA NA NA NAset.seed(115517)pts<-st_bbox(r)|>st_as_sfc()|>st_sample(20)(e<-st_extract(r, pts))# stars object with 2 dimensions and 1 attribute# attribute(s):# Min. 1st Qu. Median Mean 3rd Qu. Max.# L7_ETMs.tif 12 41.75 63 60.95833 80.5 145# dimension(s):# from to refsys point# geometry 1 20 SIRGAS 2000 / ... TRUE# band 1 6 NA NA# values# geometry POINT (293002....,...,POINT (290941....# band NULLplot(r[,,,1], reset =FALSE)col<-rep("yellow", 20)col[c(8, 14, 15, 18, 19)]="red"st_as_sf(e)|>st_coordinates()|>text(labels =1:20, col =col)