15 Measures of spatial autocorrelation
Exercise 15.1
Re-using the objects from exercise 14.3, we have:
xy <- data.frame(expand.grid(1:8, 1:8), col=rep(c(rep(c("black", "white"), 4), rep(c("white", "black"), 4)), 4))
library(stars)
# Loading required package: abind
(xy |> st_as_stars() |> st_as_sf() -> grd)
# Simple feature collection with 64 features and 1 field
# Geometry type: POLYGON
# Dimension: XY
# Bounding box: xmin: 0.5 ymin: 0.5 xmax: 8.5 ymax: 8.5
# CRS: NA
# First 10 features:
# col geometry
# 1 white POLYGON ((0.5 8.5, 1.5 8.5,...
# 2 black POLYGON ((1.5 8.5, 2.5 8.5,...
# 3 white POLYGON ((2.5 8.5, 3.5 8.5,...
# 4 black POLYGON ((3.5 8.5, 4.5 8.5,...
# 5 white POLYGON ((4.5 8.5, 5.5 8.5,...
# 6 black POLYGON ((5.5 8.5, 6.5 8.5,...
# 7 white POLYGON ((6.5 8.5, 7.5 8.5,...
# 8 black POLYGON ((7.5 8.5, 8.5 8.5,...
# 9 black POLYGON ((0.5 7.5, 1.5 7.5,...
# 10 white POLYGON ((1.5 7.5, 2.5 7.5,...
(grd$col |> factor() -> COL) |> table()
#
# black white
# 32 32
library(spdep)
rook <- poly2nb(grd, queen=FALSE)
queen <- poly2nb(grd, queen=TRUE)In the rook case, no black:black or white:white neighbours are found, differing greatly from the expected values, which are based on non-free sampling from the proportions of colours in the data. Highly significant spatial autocorrelation is detected:
(jc_r <- joincount.multi(COL, listw=nb2listw(rook, style="B")))
# Joincount Expected Variance z-value
# black:black 0.000 27.556 8.325 -9.5503
# white:white 0.000 27.556 8.325 -9.5503
# white:black 112.000 56.889 27.205 10.5662
# Jtot 112.000 56.889 27.205 10.5662In the queen neighbour case, no spatial autocorrelation is found, despite a chessboard looking spatially structured:
joincount.multi(COL, listw=nb2listw(queen, style="B"))
# Joincount Expected Variance z-value
# black:black 49.000 51.667 23.616 -0.5487
# white:white 49.000 51.667 23.616 -0.5487
# white:black 112.000 106.667 47.796 0.7714
# Jtot 112.000 106.667 47.796 0.7714This is because we have chosen to see all eight neighbour grid cells as neighbours (away from the edges of the board), so the two categories occur equally often as neighbour values, as expected.
Exercise 15.2
First, create an uncorrelated variable, and confirm that it is uncorrelated:
set.seed(1)
x <- rnorm(nrow(grd))
moran.test(x, nb2listw(queen, style="W"), randomisation=FALSE, alternative="two.sided")
#
# Moran I test under normality
#
# data: x
# weights: nb2listw(queen, style = "W")
#
# Moran I statistic standard deviate = 0.27024, p-value =
# 0.787
# alternative hypothesis: two.sided
# sample estimates:
# Moran I statistic Expectation Variance
# 0.002292497 -0.015873016 0.004518556Next inject patterning into the variable by adding a linear trend:
x_t <- x + (0.15 * xy$Var1)
moran.test(x_t, nb2listw(queen, style="W"), randomisation=FALSE, alternative="two.sided")
#
# Moran I test under normality
#
# data: x_t
# weights: nb2listw(queen, style = "W")
#
# Moran I statistic standard deviate = 3.0064, p-value =
# 0.002644
# alternative hypothesis: two.sided
# sample estimates:
# Moran I statistic Expectation Variance
# 0.186218071 -0.015873016 0.004518556Test again having taken the residuals from a linear model removing the injected trend:
lm.morantest(lm(x_t ~ xy$Var1), nb2listw(queen, style="W"), alternative="two.sided")
#
# Global Moran I for regression residuals
#
# data:
# model: lm(formula = x_t ~ xy$Var1)
# weights: nb2listw(queen, style = "W")
#
# Moran I statistic standard deviate = 0.28036, p-value =
# 0.7792
# alternative hypothesis: two.sided
# sample estimates:
# Observed Moran I Expectation Variance
# -0.012449399 -0.030600358 0.004191544This is important to understand because the spatial patterning in a variable of interest, and picked up by a global measure of spatial autocorrelation, may be driven by an omitted variable. If we cannot add that variable, a latent variable or mixed effects model may be a good choice.
Exercise 15.3
False discovery rate adjustment is required when conducting repeated tests on the same data set. Usually, local measures of spatial autocorrelation are calculated for all the observations in a data set, and so constitute repeated tests. When repeated tests are conducted, the usual reading of confidence intervals and probability values must be adjusted to take the repeated use of the data into account.
Exercise 15.4
If we start with the standard local Moran’s \(I_i\) for the random values with a slight 1D trend, upgraded to analytical conditional standard deviates, but with only the standard intercept-only mean model, we have a starting point; a fair number of the values exceed 2:
locm <- localmoran(x_t, nb2listw(queen, style="W"))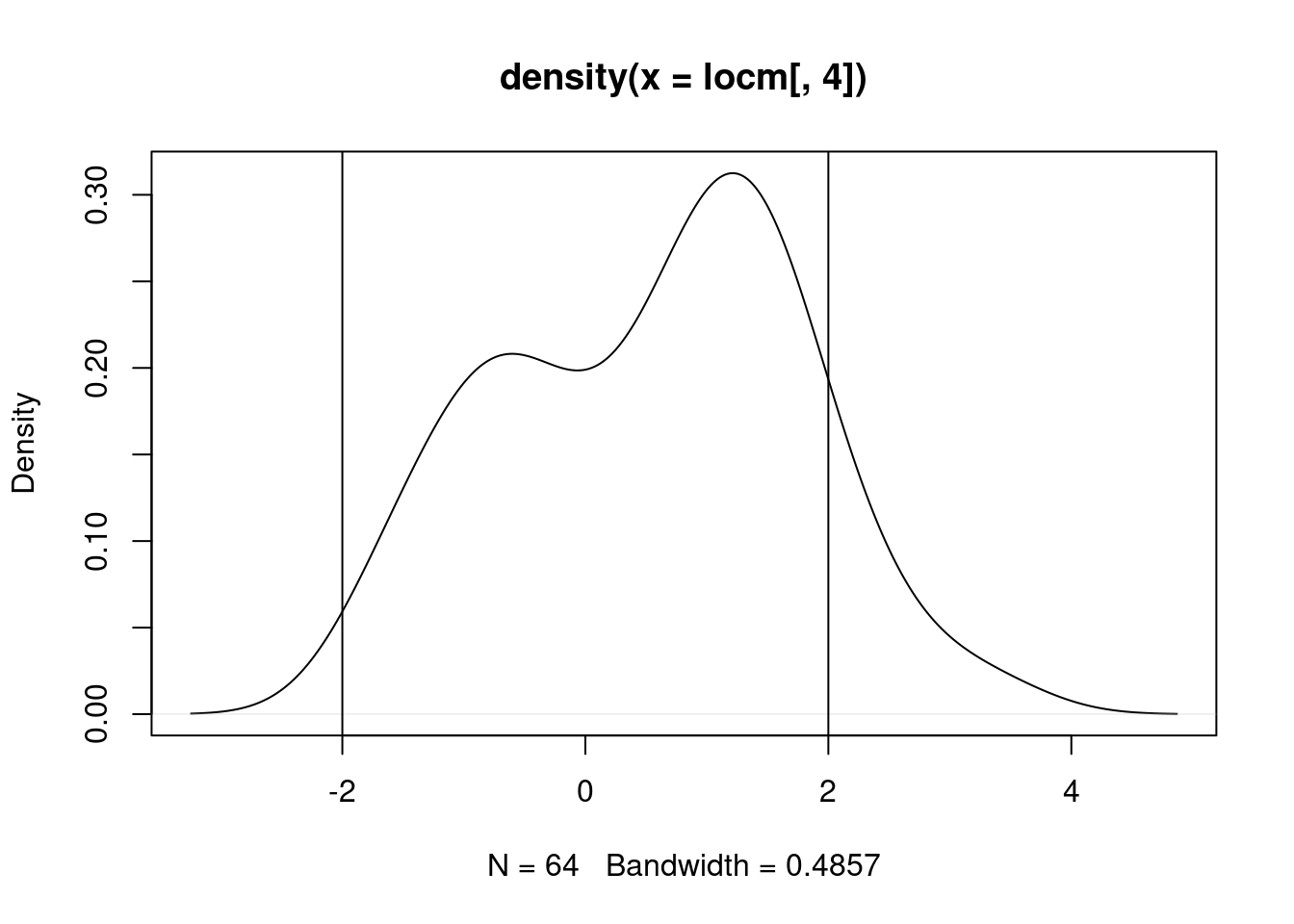
grd$locm_sd <- locm[, 4]
plot(grd[, "locm_sd"]) 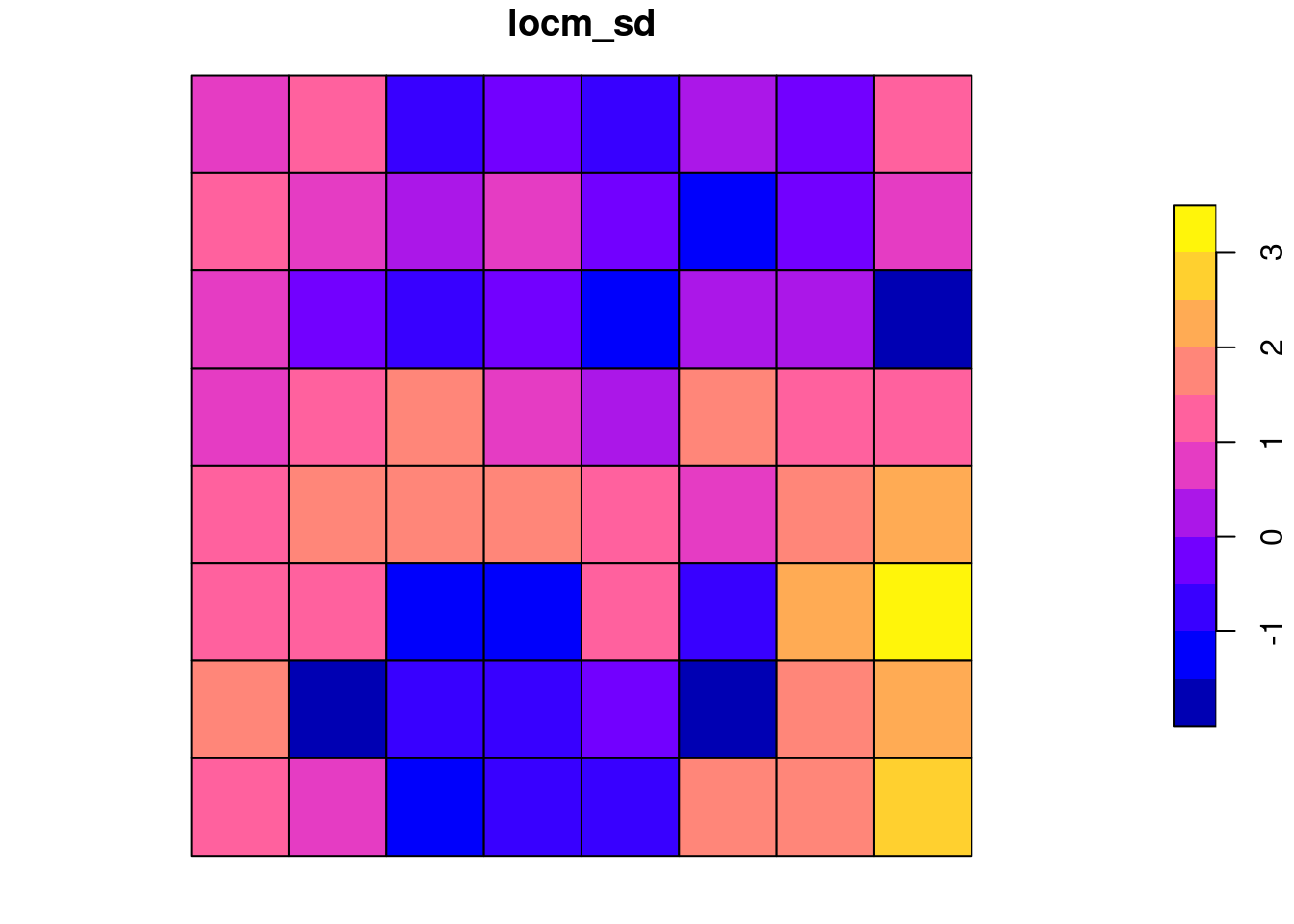
If we apply false discovery rate adjustment, we have just one significant measure:
In the first Saddlepoint approximation also for the random values with a slight 1D trend, the distribution of standard deviates shifts leftward, with both positive and negative values beyond abs(2):
lm_null <- lm(x_t ~ 1)
locm_null <- summary(localmoran.sad(lm_null, nb=queen, style="W"))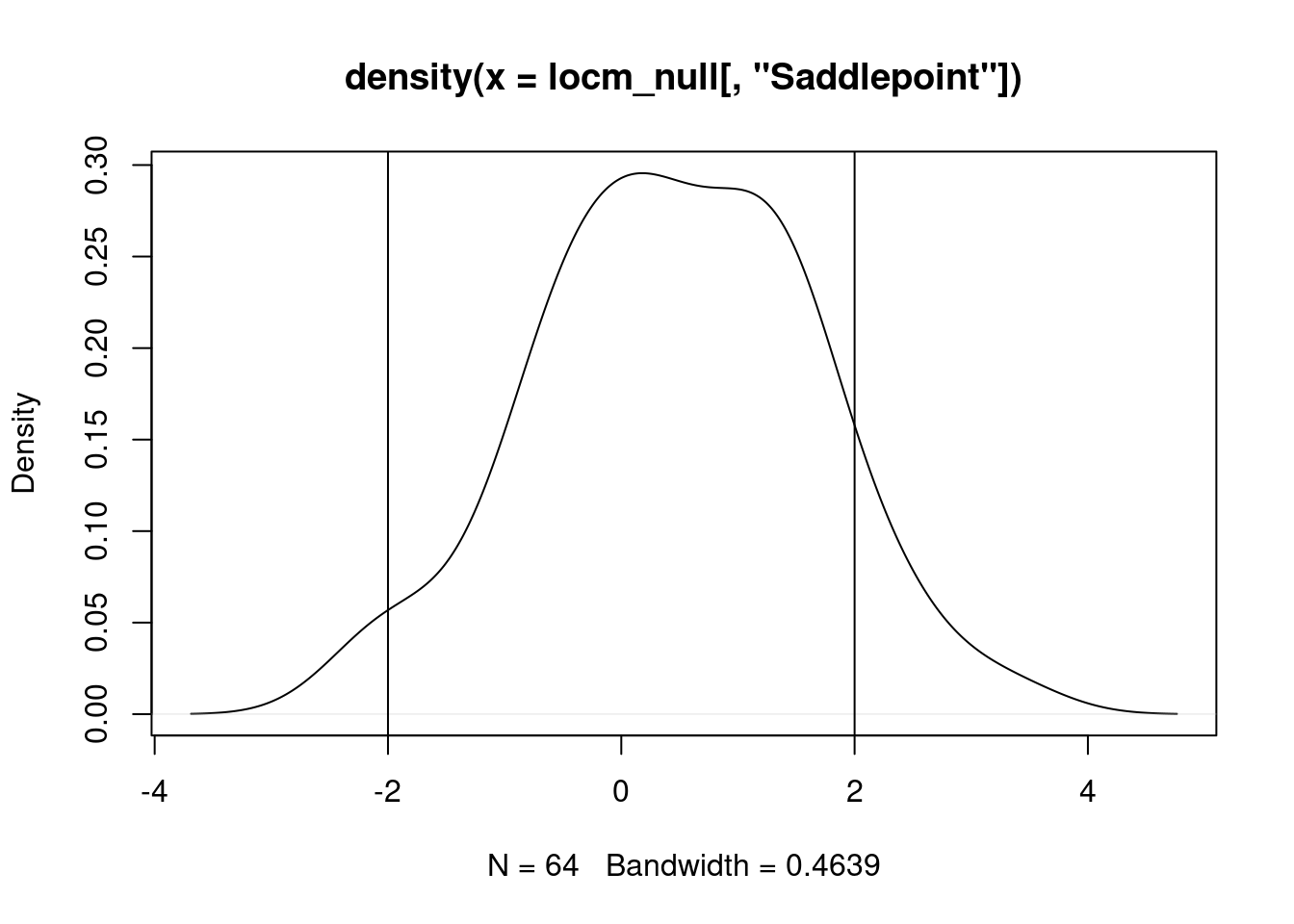
grd$locm_null_sd <- locm_null[, "Saddlepoint"]
plot(grd[, "locm_null_sd"]) 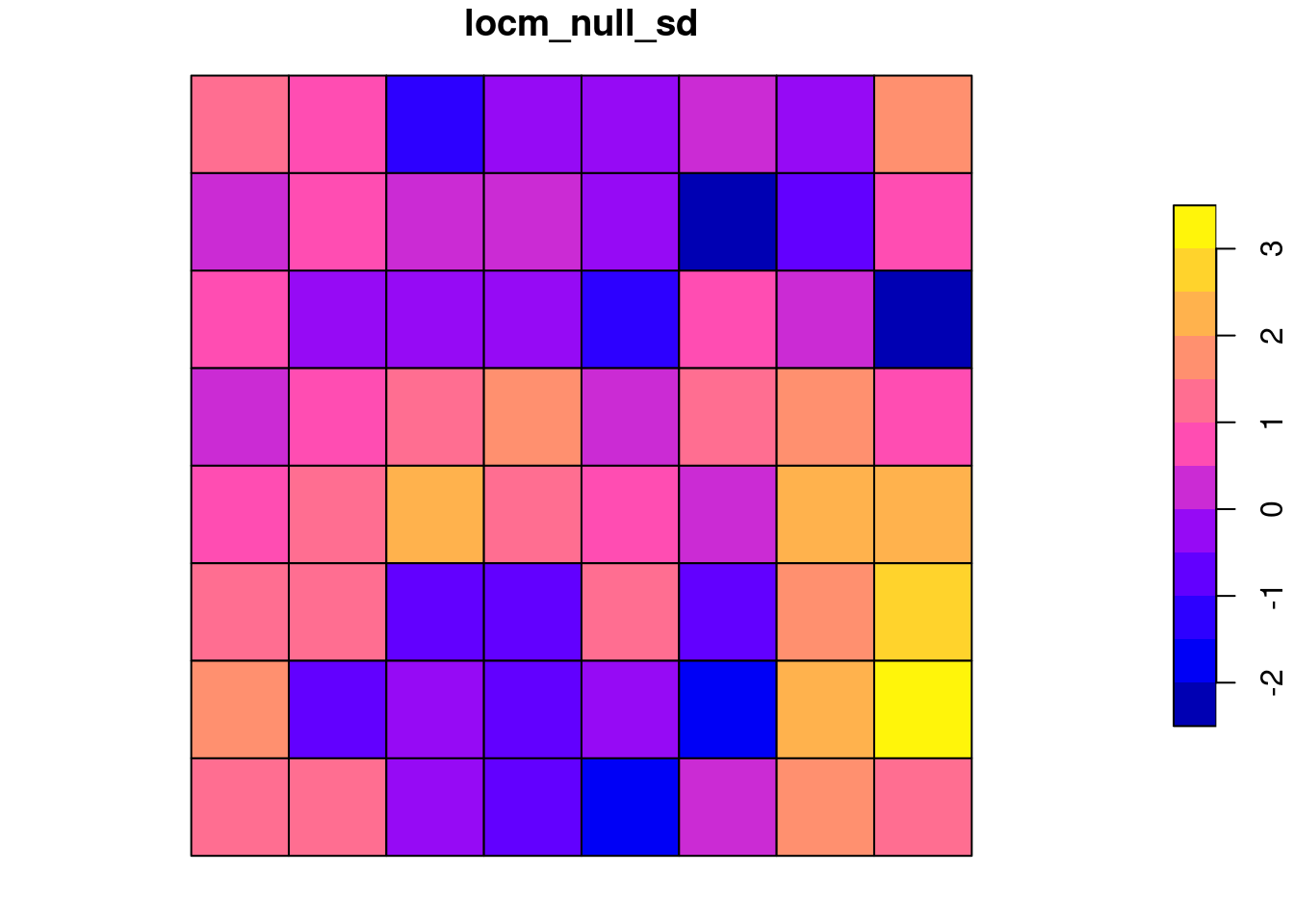
If we apply false discovery rate adjustment, we also have just one significant measure:
Once we analyse a model including the 1D trend, most of the distribution of standard deviate values is between -2 and 2:
lm_trend <- lm(x_t ~ xy$Var1)
locm_tr <- summary(localmoran.sad(lm_trend, nb=queen, style="W"))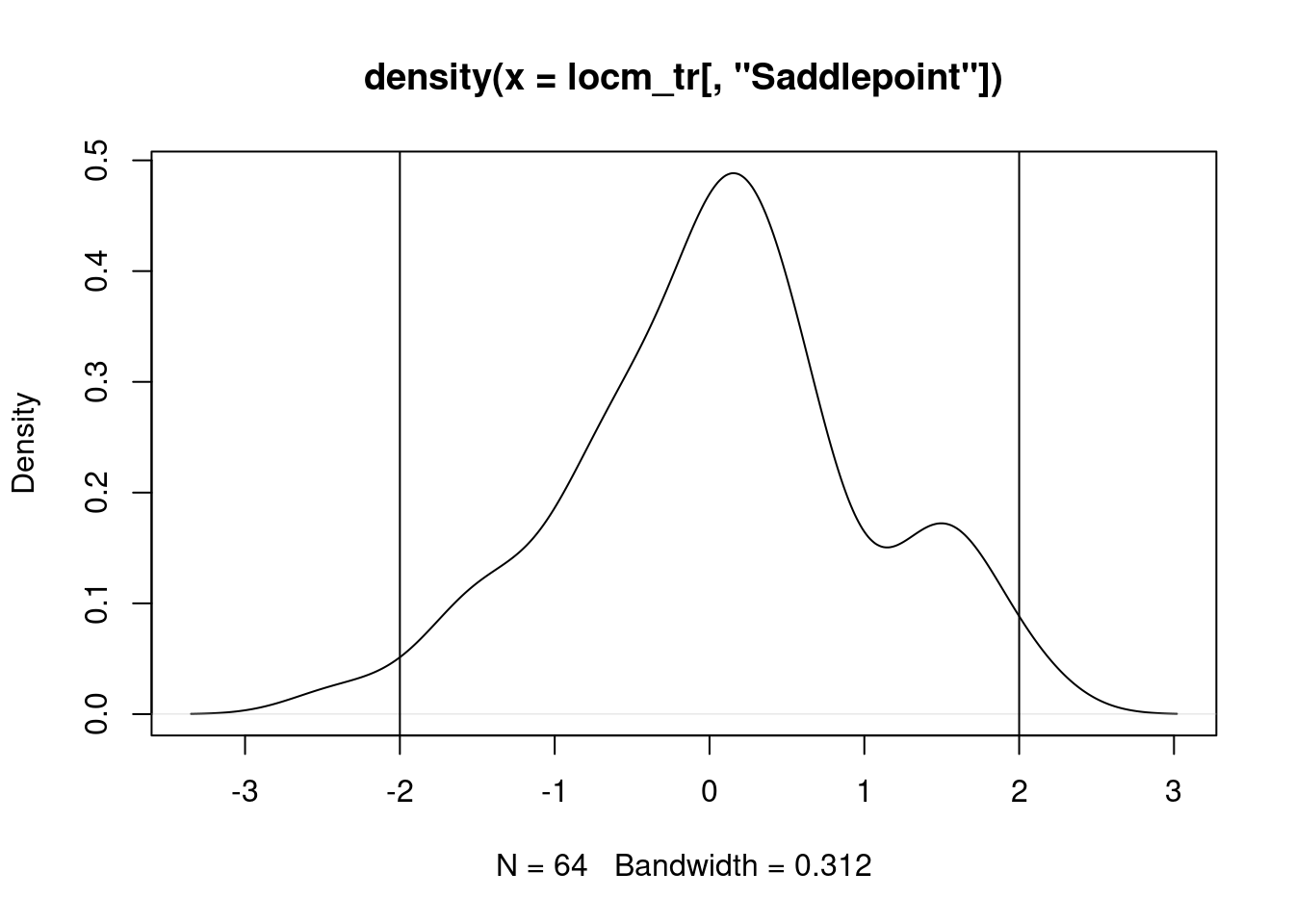
grd$locm_tr_sd <- locm_tr[, "Saddlepoint"]
plot(grd[, "locm_tr_sd"]) 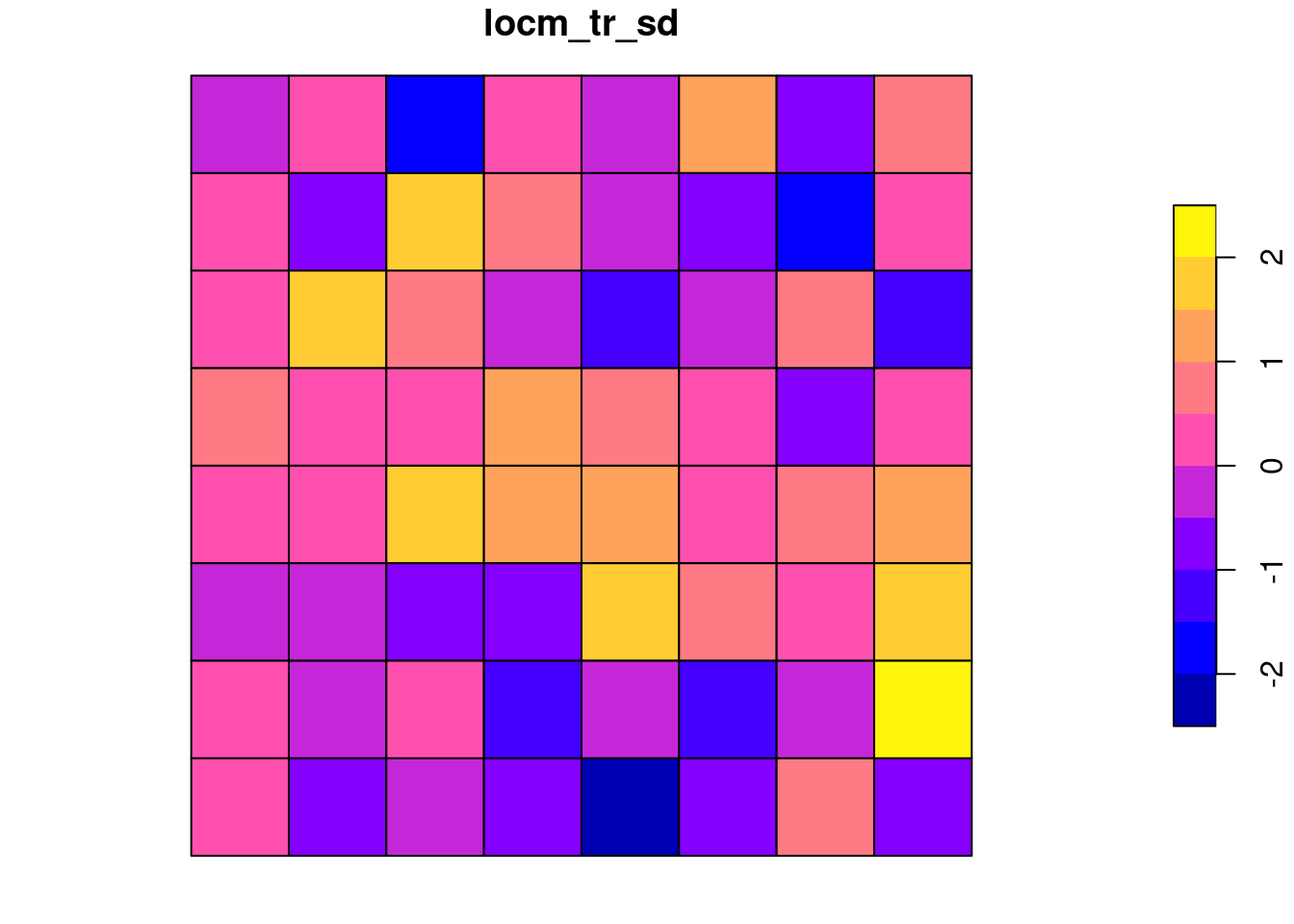
If we apply false discovery rate adjustment, we now have no significant measures, as expected:
localmoran.sad() or localmoran.exact() provide both richer mean models, and estimates of the standard deviates built on the underlying spatial relationships for each observation, rather than analytical or permutation assumptions for the whole data set. This is achieved at the cost of longer compute times and larger memory use, especially when the Omega= argument to localmoran.sad() or localmoran.exact.alt() is used, because this is a dense \(n \times n\) matrix.